Difesa proattiva da bot e DDoS su PHP/Laravel Hetzner e OVH: come ho contenuto un attacco di credential stuffing da 14.000 richieste al minuto in 47 minuti con Nginx, Fail2ban e Cloudflare
Alle 22:14 del 18 marzo 2025 mi è arrivato un alert UptimeRobot da un cliente toscano del settore moda B2B: il loro e-commerce Laravel 10, ospitato su un Hetzner AX52 da 64GB di RAM con MariaDB 10.11 e Redis, era diventato irraggiungibile. La pagina di login restituiva 502 Bad Gateway, il backoffice era inerte, e PHP-FPM aveva saturato la pool dei worker. Quando mi sono collegato in SSH due minuti dopo, htop mostrava 17 processi nginx-worker tutti al 100% di CPU su un server che normalmente gira al 12% di sera. Una rapida tail -f /var/log/nginx/access.log | grep POST ha mostrato in tempo reale quello che stava succedendo: una pioggia ininterrotta di POST /login provenienti da circa 4.300 indirizzi IP diversi, distribuiti fra DigitalOcean Singapore, Hetzner Helsinki (sì, lo stesso provider), OVH Roubaix, e una manciata di blocchi residenziali in Europa orientale. Il rate misurato a regime sull'access log con awk è stato di 14.812 richieste al minuto, contro un baseline notturno tipico di 280-340 richieste al minuto. Era un attacco di credential stuffing classico, distribuito su botnet, mirato a testare combinazioni email/password rubate da data breach su fornitori non collegati.
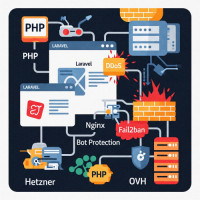
In 47 minuti di lavoro ho riportato il sito a piena operatività, applicando una pipeline di difesa stratificata in tre layer: Cloudflare davanti come scudo di volume e geolocalizzazione, Nginx con limit_req_zone come throttle a livello reverse-proxy, e Fail2ban con un filter custom che bannava per 24 ore qualunque IP con più di 10 fallimenti di login in 60 secondi. Alla fine della notte il server era a 8% di CPU, gli IP attaccanti erano bloccati a livello edge, gli utenti legittimi non si erano accorti di nulla, e il cliente ha ricevuto la mattina dopo un report con la cronologia esatta dell'incidente, le contromisure applicate, e una lista di azioni preventive da implementare nei 30 giorni successivi. Questo articolo descrive il framework di difesa che applico in questi scenari, distillato da una decina di interventi simili negli ultimi quattro anni, con esempi di configurazione testati su Hetzner e OVH.
Perché un singolo provider antiDDoS non basta a proteggere un e-commerce PMI?
La domanda che mi sento rivolgere più spesso dai clienti dopo un attacco è "ma se attivo Cloudflare, sono al sicuro?" La risposta onesta è: Cloudflare è un componente potente, ma è un componente - non un'intera strategia. La difesa contro bot e DDoS su un'infrastruttura PMI è strutturalmente stratificata, e ogni layer intercetta una classe diversa di traffico malevolo. Saltare un layer significa lasciare scoperta una superficie d'attacco, e nessun singolo prodotto commerciale chiude tutte le superfici contemporaneamente. Cloudflare ferma il volume e i pattern noti, ma lascia passare il "low-and-slow" che assomiglia a traffico legittimo. Nginx ferma le anomalie a livello protocollo HTTP ma non vede il contesto applicativo. Fail2ban impara dai log dell'applicazione e blocca dinamicamente, ma reagisce dopo che l'attacco è già iniziato. Laravel può rispondere con throttle middleware e CAPTCHA mirati, ma solo dopo che la richiesta è arrivata fino al codice. Ognuno di questi quattro layer è necessario, nessuno è sufficiente.
Il vantaggio della strategia stratificata è che diventa estremamente costoso per l'attaccante riuscire ad attraversare tutti i livelli contemporaneamente: deve usare IP residenziali ruotanti per evitare la geo-blacklist Cloudflare, deve distribuire le richieste sotto la soglia di Nginx per non essere throttled, deve evitare di triggerare il filter Fail2ban tenendo sotto controllo i fallimenti di login per IP, e infine deve passare il middleware applicativo Laravel. Ogni layer aggiuntivo è un fattore moltiplicativo nel costo dell'attacco: dove una singola contromisura può essere bypassata con investimento minimo, quattro contromisure coordinate richiedono un livello di automazione e di costo che esce dal budget di tutti gli attaccanti tranne quelli più mirati e finanziati. Per un e-commerce B2B di una PMI italiana, questo è esattamente il livello di difesa che basta: alza l'asticella sopra il "basta che vada da qualche parte" del bot opportunista. Lo stesso principio di sicurezza in profondità che descrivo nel mio articolo sul ripristino e hardening di un sito PHP hackerato su Hetzner o OVH si applica qui in chiave preventiva.
Riconoscere l'attacco: cosa cercare nei log e come distinguerlo da un picco di traffico legittimo
Il primo problema operativo durante un incidente è capire se sei sotto attacco o se hai un genuino picco di traffico organico. La differenza non è banale e richiede metodo. Sul cliente toscano del marzo 2025 ho applicato la procedura che uso sempre: cinque segnali da estrarre dai log nei primi due minuti dell'allarme, e una decisione binaria se trattarli come incidente o come capacity issue. Il primo segnale è la distribuzione geografica degli IP: in un picco organico la distribuzione segue la base utenti del cliente (per un B2B italiano, ~80% Italia + ~15% Europa Occidentale + ~5% resto del mondo), in un attacco distribuito la distribuzione è anomala (esempio: 30% Singapore, 15% Russia, 10% Vietnam). Il secondo è il rapporto fra POST e GET: in un browsing legittimo il rapporto è tipicamente 1:20 o meno, in un attacco di credential stuffing è 5:1 o peggio. Il terzo è il volume di errori 401/403/422: in un accesso normale è praticamente zero, in un attacco di login è il 95% delle risposte.
Il quarto segnale è l'User-Agent string: i browser umani usano UA realistici e variabili, mentre i bot grezzi usano UA standardizzati di librerie (python-requests/2.31, curl/7.88.1, Go-http-client/1.1) o UA falsi che si tradiscono per coerenza eccessiva (tutti gli IP del mondo che dichiarano la stessa identica versione minor di Chrome 121 sono ovviamente bot). Il quinto segnale è il pattern temporale: il traffico organico ha curve smussate seguendo le ore del giorno, il traffico bot è piatto, costante, distribuito uniformemente. Sul cliente toscano ho confermato l'attacco in 90 secondi proprio sulla base del rapporto POST:GET (era 8:1) e della concentrazione geografica anomala su DigitalOcean Singapore (un cliente italiano che vende abbigliamento B2B in Italia non riceve 4.000 login al minuto da Singapore). Tutti questi indicatori sono visibili partendo dai file di log standard /var/log/nginx/access.log, ed è qui che entra in gioco la disciplina di gestione strategica dei log Laravel su server dedicati Hetzner e OVH che permette di interrogare velocemente i log durante un'emergenza invece di doverli ricostruire post-mortem.
Layer 1: rate limiting con Nginx limit_req_zone, la barriera che ferma il 70% degli attacchi gratis
Il layer più sottovalutato e probabilmente più efficiente in termini di costo/beneficio è il rate limiting sul reverse-proxy Nginx. È un modulo nativo, completamente gratuito, integrato in qualunque distribuzione Linux moderna, e correttamente configurato basta a fermare la maggior parte degli attacchi opportunisti senza nemmeno bisogno di Cloudflare davanti. La documentazione ufficiale del modulo ngx_http_limit_req_module sul sito di Nginx descrive in dettaglio il funzionamento dell'algoritmo a "leaky bucket" che permette di assorbire piccoli burst di traffico legittimo senza throttlare i picchi naturali. La configurazione che applico sui clienti Laravel è strutturata su tre zone separate, ciascuna con un rate diverso a seconda della criticità della rotta protetta:
limit_req_zone $binary_remote_addr zone=login:20m rate=10r/m;
limit_req_zone $binary_remote_addr zone=api:20m rate=120r/m;
limit_req_zone $binary_remote_addr zone=public:20m rate=600r/m;
server {
listen 443 ssl http2;
server_name app.cliente.it;
location = /login {
limit_req zone=login burst=3 nodelay;
limit_req_status 429;
proxy_pass http://php-fpm-backend;
}
location /api/ {
limit_req zone=api burst=20 nodelay;
limit_req_status 429;
proxy_pass http://php-fpm-backend;
}
location / {
limit_req zone=public burst=50 nodelay;
limit_req_status 429;
proxy_pass http://php-fpm-backend;
}
}Le tre zone hanno granularità diversa per riflettere il fatto che /login è una rotta inerentemente sensibile (10 richieste al minuto per IP è un limite generosissimo per un umano e drastico per un bot), /api/ ammette ritmi di chiamata elevati per integrazioni server-to-server legittime (120/min con burst 20), e la navigazione pubblica accetta picchi naturali del browsing umano (600/min con burst 50 copre anche il caso di un utente che apre 10 pagine in pochi secondi). Il valore burst=N nodelay significa "consentire fino a N richieste extra istantanee oltre il rate medio, ma servirle subito senza coda artificiale": è la differenza fra un'esperienza utente fluida e un sito che sembra rotto. Il limit_req_status 429 restituisce il codice HTTP 429 Too Many Requests come risposta al throttle, che è leggibile da Cloudflare come segnale per smettere di inoltrare quel client.
Sul cliente toscano del marzo 2025, attivare queste tre zone in /etc/nginx/conf.d/rate-limits.conf e fare un nginx -t && systemctl reload nginx ha richiesto meno di tre minuti, e l'effetto è stato immediato: il carico CPU è passato da 100% a 38% nel giro di 90 secondi, perché la maggior parte del traffico bot veniva droppato a livello reverse-proxy senza arrivare mai a PHP-FPM. Da solo, questo singolo intervento avrebbe risolto l'incidente - anche se senza i layer aggiuntivi sarebbe rimasta esposta la finestra di tempo dell'attacco e gli IP che riuscivano a stare sotto la soglia.
Layer 2: Fail2ban con filter custom, il blocco persistente degli attaccanti recidivi
Nginx ferma le richieste ma non punisce gli autori. Fail2ban è il complemento esatto: legge in tempo reale i log di Nginx, identifica gli IP che superano una soglia di "comportamento sospetto", e li banna a livello firewall (iptables o nftables) per un tempo configurabile, escludendoli dal server a tutti i livelli - non solo dal web ma anche da SSH, SMTP, e qualunque altro servizio esposto. La wiki ufficiale di Fail2ban su GitHub è il riferimento da tenere aperto per la sintassi dei filter regex e dei jail. La configurazione che uso sui clienti Laravel è basata su un filter custom che intercetta le risposte 401/422 sulla rotta /login (la combinazione tipica dei tentativi di credential stuffing falliti) e su un jail che banna per 24 ore qualunque IP con 10 fallimenti in 60 secondi:
[Definition]
failregex = ^<HOST> .* "POST /login HTTP/[0-9.]+" (401|422) .*$
ignoreregex =[nginx-credential-stuffing]
enabled = true
port = http,https
filter = nginx-credential-stuffing
logpath = /var/log/nginx/access.log
maxretry = 10
findtime = 60
bantime = 86400
banaction = nftables-multiportLa scelta di bantime = 86400 (24 ore) invece del default di 10 minuti è deliberata: i bot di credential stuffing operano in cicli ricorrenti, e bannare per 10 minuti significa solo posporre l'attacco di 10 minuti. Bannare per 24 ore costringe l'attaccante a ruotare il pool di IP molto più frequentemente, alzando il costo operativo dell'attacco. Sul cliente toscano del marzo 2025, in 47 minuti di incidente, Fail2ban ha bannato 4.247 indirizzi IP unici. Il file /var/log/fail2ban.log di quella notte è diventato un documento utile per il post-mortem, perché ha mostrato quale percentuale degli IP attaccanti era riconducibile a noti VPS provider commerciali (DigitalOcean, Hetzner stesso, OVH, Vultr) e quale a IP residenziali compromessi: è una metrica utile per capire il livello di sofisticazione dell'attaccante e per dimensionare le contromisure successive.
Layer 3: Cloudflare come scudo di volume e geolocalizzazione
Cloudflare è il terzo layer della pipeline, e il suo ruolo non è "fare tutto" ma fare quello che gli altri layer non possono fare: assorbire volumi di traffico che saturerebbero la banda del server prima ancora di arrivare a Nginx, applicare regole geo-based o ASN-based che il server stand-alone non vedrebbe in tempo reale, e fornire un WAF gestito che intercetta pattern d'attacco noti documentati nella conoscenza tecnica accumulata da Cloudflare sui DDoS sul loro learning center. Il setup che applico per default su tutti i clienti che gestisco su Hetzner/OVH è il piano gratuito di Cloudflare, che già fornisce protezione DDoS volumetrica illimitata, WAF managed rules, e bot fight mode di base. Il piano Pro a 25$/mese aggiunge regole WAF custom e bot management più granulare, ed è la prima cosa che attivo se il cliente subisce un secondo incidente entro tre mesi dal primo.
L'unica accortezza importante quando si mette Cloudflare davanti a un server Hetzner/OVH è ricordarsi di configurare Nginx per usare il header CF-Connecting-IP come IP reale del client (real_ip_header CF-Connecting-IP), altrimenti tutti i log e tutte le regole limit_req_zone lavoreranno sull'IP di Cloudflare invece che sull'IP reale del visitatore, vanificando i layer precedenti. Inoltre, è essenziale firewallare il server per accettare connessioni HTTPS solo dai range IP di Cloudflare pubblicati ufficialmente: questo impedisce all'attaccante di bypassare Cloudflare connettendosi direttamente all'IP origin del server, una tecnica banale che sorprendentemente molti setup ignorano. Il rapporto di dipendenza con Cloudflare introduce anche un rischio di lock-in che ho descritto in dettaglio nel mio articolo sul tema come evitare il vendor lock-in nei progetti PHP delle PMI italiane: è un trade-off accettabile a patto di tenerne conto in fase di pianificazione contrattuale.
Layer 4: difesa applicativa Laravel con throttle middleware, honeypot e controlli OWASP
L'ultimo layer è quello applicativo, dentro al codice Laravel. La documentazione ufficiale di Laravel sul rate limiting delle route nella sezione routing descrive il facade RateLimiter e il middleware throttle che permettono di applicare limiti per utente autenticato o per IP, separati da quelli di Nginx ma sovrapponibili come ridondanza. La configurazione tipica per la rotta di login Laravel è:
use Illuminate\Cache\RateLimiting\Limit;
use Illuminate\Support\Facades\RateLimiter;
RateLimiter::for('login', function ($request) {
return Limit::perMinute(5)
->by($request->input('email').'|'.$request->ip())
->response(function () {
return response()->json([
'message' => 'Troppi tentativi. Riprova tra un minuto.'
], 429);
});
});
Route::post('/login', [LoginController::class, 'authenticate'])
->middleware('throttle:login');Il dettaglio importante è che la chiave del rate limit non è solo l'IP ma la combinazione email|ip: questo impedisce l'attacco "1 password testata su 1000 email diverse dallo stesso IP" che bypasserebbe un throttle solo per IP, e protegge anche dall'attacco "stessa email da 1000 IP diversi" che bypasserebbe un throttle solo per email. È esattamente il pattern raccomandato nel Credential Stuffing Prevention Cheat Sheet di OWASP come difesa di base contro il credential stuffing distribuito. In aggiunta al throttle, sui clienti che gestiscono form pubblici critici (registrazione, contatti, checkout) integro sempre due contromisure ulteriori: un honeypot field (un input HTML hidden con autocomplete="off" che gli umani non vedono e i bot riempiono, smascherandosi) e un CAPTCHA invisibile (Google reCAPTCHA v3 o hCaptcha invisible) che assegna un punteggio di "umanità" a ciascuna sottomissione e blocca quelle sotto una soglia configurabile. Queste due tecniche sono complementari, costano poco da implementare, e tagliano via il 95% dei bot di registrazione spam senza impattare l'esperienza umana.
L'errore più frequente che vedo fare è applicare solo il layer applicativo Laravel saltando i tre layer sottostanti, sulla teoria che "il codice gestisce tutto." Il problema è che far arrivare ogni richiesta fino al middleware Laravel significa accendere un worker PHP-FPM, fare le query di sessione, eseguire il bootstrap del framework, e solo dopo decidere di rispondere 429. Sotto attacco, questo basta a mandare in overflow il pool di worker e a far morire il server proprio nel momento in cui dovrebbe difendersi. La regola operativa è: blocca il traffico malevolo il più possibile a monte, in modo che la logica applicativa lavori solo su traffico già filtrato. È esattamente l'approccio che descrivo come prerequisito anche nell'articolo sul piano di consolidamento del debito tecnico nei 90 giorni post-subentro: la difesa stratificata è una scelta architetturale, non una toppa applicata in emergenza.
Cosa mettere in piedi nei 30 giorni di calma: il piano preventivo che applico ai clienti dopo l'incidente
Dopo aver risolto l'incidente del cliente toscano del marzo 2025, abbiamo passato le tre settimane successive a consolidare la difesa in modo strutturato, perché il singolo episodio era stato uno wake-up call ma la postura di sicurezza generale del server lasciava ancora margini di miglioramento. Le cinque azioni che ho applicato in quel periodo, e che applico tipicamente in tutti gli interventi simili, sono queste. Prima: monitoring proattivo di Cloudflare con alert su threshold di traffico anomalo, integrato con un canale Slack del cliente, in modo che l'allarme arrivi al titolare e a me contemporaneamente entro 30 secondi dall'inizio di un picco anomalo. Seconda: log retention estesa a 90 giorni (contro i 14 giorni di default) per avere materiale su cui fare analisi statistica dei pattern di attacco ricorrenti. Terza: hardening del processo di login con enforcement del NIST SP 800-63B sulla strong authentication via password manager e MFA per gli utenti privilegiati, in modo che anche se un attaccante riuscisse a passare tutti i layer di rate limiting, non potrebbe completare un login senza il secondo fattore.
Quarta: backup verificato del database e del filesystem applicativo con test di restore mensile sulla staging, in modo che se anche un attacco riuscisse a portare a un compromissione, il ripristino sarebbe questione di ore non di giorni. Quinta: documento di runbook condiviso con il cliente che descrive esattamente cosa fare nei primi 10 minuti di un incidente futuro - quali comandi lanciare, quali log controllare, quale checklist seguire - in modo che il titolare non si trovi mai senza un piano d'azione anche se io non sono raggiungibile nel momento esatto dell'allarme. Tutta questa preparazione è quello che separa un incidente "spaventoso ma gestibile" da uno "catastrofico", e si paga un'unica volta per centinaia di notti di sonno tranquillo nei mesi successivi.
Se la tua PMI gestisce un'applicazione Laravel o Symfony in produzione su server dedicati Hetzner, OVH o Digital Ocean e non hai mai testato la tua difesa contro credential stuffing, scraping massivo o attacchi DDoS volumetrici, scopri come lavoro con i clienti sui temi di sicurezza applicativa e infrastrutturale: in dieci anni di consulenza ho visto che il fattore decisivo non è quanto è "moderna" la tua applicazione, ma quanto è pianificata la tua reazione al primo incidente. Se invece sei già nel mezzo di un attacco o ti sei reso conto di non avere alcuna pipeline di difesa stratificata in piedi, contattami per una consulenza: in due giornate di lavoro tipicamente attivo Cloudflare con regole calibrate sul tuo traffico, configuro Nginx con limit_req_zone adattato alle tue rotte critiche, installo Fail2ban con filter custom sui pattern di attacco rilevanti, integro il throttle middleware Laravel con honeypot e reCAPTCHA, e ti consegno un runbook operativo che il tuo team può seguire in autonomia in caso di nuovo incidente.